「對研究腦科學的人來說,這真是一個最好的時代。」這句話,是國立中央大學認知神經科學研究所吳嫻教授對其研究旅程的最佳註腳。在這個時代,科技進步讓腦科學的研究工具與方法日新月異,大腦不再是不可觸及的神秘境地,而是可以一步步解開的謎題。
吳嫻的學術旅程,也充分體現了對大腦奧秘的探索精神。從工科背景出發,因對人類行為及其背後原因的好奇,吳嫻跨界進入心理學領域,並在美國完成博士學位。回國後,她將心理學與行為科學相結合,開啟了大腦的研究之旅。

中央大學認知神經科學研究所吳嫻教授
拍攝/馬藤萍
大腦自動導航的秘密:統計學習
在接觸心理學後,吳嫻便深深著迷於人類行為背後的規律與機制。「你是否曾注意到,大腦似乎擁有一種無需指引的天賦?這種本能幫助我們在所經驗到的偶然事物中捕捉規律,最終從這些看似隨機的片段中,拼湊出對世界的理解和有意義的知識。」
這種「天賦」的背後蘊藏著「統計學習」(statistical learning)的奧秘——大腦在無意識中辨識、提取規律的能力,在語言習得、視覺辨識與行為模式的形成中扮演了關鍵角色。因此統計學習也和認知心理學(cognitive psychology)、神經語言學(neurolinguistics)密切相關,透過探討人類如何感知、處理並利用規律訊息的運作原理,可看出統計學習能力的貢獻。
簡單來說,統計學習就是「抓規則」的本事。這一能力的「學名」源自於1997 年的一項經典實驗。研究者播放一段由無意義單音節組成的兩分鐘語音流給八個月大的嬰兒聽,例如:pabikutibudogolatupabikudaropitibudo⋯⋯。
整段語音流聽起來像一連串隨機的音節組合,但其中一些音節(如 pa、bi 和 ku)總是以固定順序相連出現,形成三位一體的穩定組合,讓嬰兒逐漸意識到它們可能屬於一個「單字」。然而,當語音流從pabiku過渡到後續的音節tibudo,由於這兩組單字之間的音節連接是不固定的,ku不一定總是連接到ti。此時,這種較低機率出現的音節連接方式使得嬰兒難以預測下一個音節,從而形成一種「鬆散」的連結。
這種機率分布的差異幫助嬰兒識別出穩定的音節組合(如 pabiku 是一個單字)和隨機連接的部分(單字之間的邊界),使他們能從連續的語音流中提取出可能的「單字」。進一步來說,雖然 ku 之後的連接音節是不固定的,但隨著長時間的聆聽,嬰兒能夠再識別出新的單字。例如,重複出現的tibudo可能也是一個單字。

八個月大的嬰兒能通過語音流學習音節規律,顯示統計學習是與生俱來的本能。
圖片來源/Adobe Stock
更進一步來說,大腦天生擅長辨識規律,像是內建了 GPS 系統。在實驗中,嬰兒在聽到不熟悉的音節時會覺得特別新奇,展現出了優異的抓取規律的能力。即使沒有外部教學或學習動機,他們仍能迅速的從看似隨機的語音流中,自動提取結構與規律。這種統計學習能力被認為是一種與生俱來的大腦機制,幫助我們在陌生事物的迷霧中找到方向。
從規律感知到語言學習
既然統計學習揭示了語言學習中規律感知的基礎,那麼「中文」這種視覺複雜度特別高的書寫系統,是否也有其獨特的學習模式?如果中文學習者有感受到音旁和意旁在功能上的差異,他們的大腦會不會以不同方式處理音旁和意旁?
吳嫻表示:「語言學習並不只是靠記憶硬背單字和語法。從神經語言學角度看,語言充滿規律,學習過程依靠對這些規律的感知與掌握,也就是語感。」她進一步問道:「我們作為中文母語者,在記住中文字時,會將音旁與意旁拆解之後分別處理嗎?還是僅僅像記圖畫一樣記下每個字而已?」
為了解答這些問題,吳嫻與研究團隊設計了一系列受到中文啟發的實驗,招募中文母語者與拼音語言使用者(如印尼語、法語等)進行比較。吳嫻解釋,中文母語人士通常能自動內化中文的字形結構和構字規則,而其他的拼音語言使用者,則需要透過具體、明顯的學習過程才能逐漸感知這些特徵。透過比較這兩類群體的表現,能更全面地理解中文學習的獨特機制。
她分享了比較不同語言經驗的受試者,在「假字判斷作業」(Chinese Lexical Decision Test)中所得到的實驗結果。由於中文字形結構中的音旁與意旁往往反映隱含的規律性,但對於以拼音語言(如英文)為母語的使用者來說,在感知中文字形結構方面可能因經驗不足而存在一定局限。因此他們提供了一系列「真字」、「假字」與「非字」,讓參與者判斷它們是否「看起來像是一個可能存在的中文字」:
- 真字(real characters):真實存在的中文字,符合語言規律且有語義,例如:「很」、「浪」。
- 偽字(pseudo-characters):將中文音旁或意旁進行組合,但並非真實存在、有意義的中文字,例如:「𢭗」。
- 非字(non-characters):完全不符合中文結構的筆畫組合,例如:「缶彳」。

「假字判斷測試」不僅考驗參與者的語言能力,也挑戰他們對中文字形結構的掌握。
圖片製作/馬藤萍。參考來源/吳嫻,「統計學習&神經美學」簡報。
研究結果顯示,中文母語者在辨識能力上表現更佳,即使是在區分同樣符合中文構字規則的「真字」與「偽字」方面,也不會遇到困難,反映出他們對實際存在之漢字的高度熟悉。這個作業的關鍵操弄,是檢測並非以中文為母語的外籍人士是否能辨別「偽字」與「非字」的不同;通常隨著學習中文的時間增加,他們對中文字形結構規律的理解逐漸加深,便越能夠看出「偽字」和「真字」的相似之處,對於「偽字」與「非字」的判斷能力也隨之提升。有趣的是,吳嫻和研究生的實驗結果發現:對於中文程度相當的外籍人士來說,他們的統計學習能力越優異,對中文構字規則的掌握就越好,很可能會幫助他們更容易習得中文的書寫系統。這樣的結果和吳嫻之前發表的功能性核磁共振造影(fMRI)結果互相呼應,顯示統計學習能力較佳的受試者,大腦花費較少的認知資源就可對中文「偽字」進行判斷。
吳嫻指出,這些實驗除了探索中文學習的機制,並了解外籍學生是否具備「中文腦」之外,還能為教材設計提供靈感。若將形聲字集中教學,比如「青」的字族:「晴」天、「清」澈、心「情」等,可幫助非母語者快速掌握規律,減輕學習負擔,也為所謂的「字帶字教學法」、「集中識字法」提供支持的證據。此外,對於統計學習能力較弱的群體,設計出具有規律性與空間感的互動遊戲,也可能是提升字形規律感知力的有效方式,能取代枯燥的死記硬背。
中文字的空間奧秘
從統計學習的角度出發,中文部件特有的「空間規律」也吸引了吳嫻的濃厚興趣。為探究對空間規律之敏感度的個別差異,研究團隊設計了一項「空間位置統計學習」作業(Spatial Positional Statistical Learning),他們利用40個幾何圖形組成固定的組合,以隨機的順序展示給參與者,分兩階段進行實驗:
- 熟悉學習階段(familiarization phase)
參與者先被動觀看幾何圖形兩兩配對出現的組合,在看似毫無章法的刺激材料配對組合中,其實每個幾何圖形出現在組合左邊或右邊位置的規律始終不變,而每個組合在螢幕上呈現的時間為2.4秒。另外,每個組合之間,畫面都會出現一個持續0.8秒的固定十字,提醒參與者集中注意力,準備迎接下個幾何圖形組合。
此階段的目的是要讓參與者學習一種新的空間排列規律。雖然組合的出現順序是隨機的,但每個幾何圖形的位置始終固定,即有一半的幾何圖形總是位於組合的左側,另一半則在右側。
圖片製作/馬藤萍。參考來源/吳嫻,「學習統計&神經美學」簡報。 - 測試階段(Testing Phase)
為確認實驗參與者在熟悉階段真的有學到各幾何圖形的空間位置這項規律,而不是硬記下曾經看過的組合,在測試階段會使用在學習階段沒有出現過的新幾何圖形,和曾經出現過的舊幾何圖形組合在一起,作為題目。這些題目包含兩種形式:
- 熟悉度判斷(Familiarity Judgment):參與者需從兩組圖形中選出「感覺更熟悉」的一組;儘管在兩個選項中的組合,在熟悉階段都沒有出現過,但有一個選項的舊幾何圖形是出現在和熟悉階段相同的位置。若參與者有掌握到各幾何圖形的空間規律,他們應該可以選出和熟悉階段中的位置規律相符合的選項。
- 位置辨別(Recognition):畫面上會出現一個新幾何圖形以及一個問號(代表要填入的答案);參與者需根據先前學到的空間規律,選擇適合填入問號位置的幾何圖形。
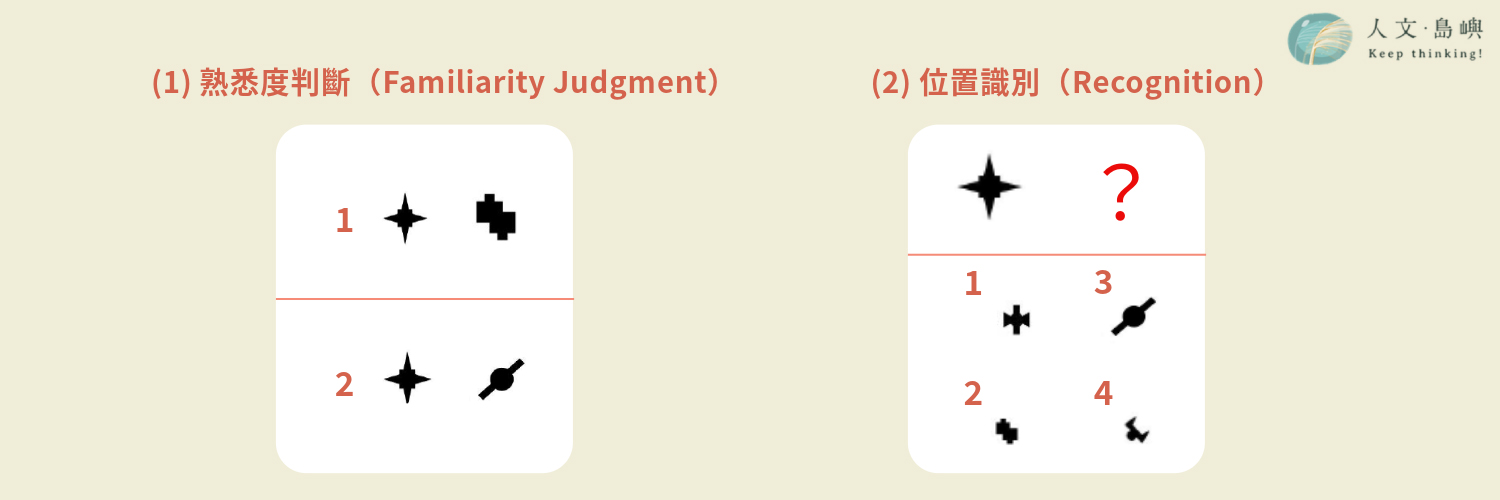
圖片製作/馬藤萍。參考來源/吳嫻,「統計學習統計&神經美學」簡報。
吳嫻指出,中文是一種比拼音文字更依賴空間訊息來展現其構字規律的書寫系統。這種文字結構上的差異,可能讓經年累月閱讀中文的母語使用者在學習空間規律時具有獨特的認知優勢。
正如前文提到,中文字形中的音旁與意旁在中文方塊字中的位置相對固定,形成比拼音文字中的字母更穩定的空間規律。相比之下,拼音語言(如英語或法語)則採用線性排列的字母系統,許多字母都可以出現在各個不同的序列位置,比中文部件缺乏空間上的結構固定性。拼音語言的單詞意義更多依賴字母序列的組合,而非空間分布。
基於此,實驗選用幾何圖形取代真實文字,避免參與者依賴語言記憶進行推理,以純粹測試他們的統計學習能力。測驗結果顯示,中文母語者確實有比希伯來文母語者更佳的空間規律敏感度,而採用相同刺激材料的電生理實驗,更進一步呈現中文母語者對空間規律的敏感度,反映在和外籍人士不同的腦電波指標上。這樣的研究結果也暗示著,外籍人士在接觸中文之後,其空間規律敏感度可能會逐漸提升,即語言環境對統計學習能力會發揮潛在影響。隨著持續學習,母語並非為中文者不僅能熟悉中文字形的空間規律,還能在此過程中發展出一種與中文密切相關的空間規律學習能力。

拍攝/馬藤萍
從統計學習到語言掌握,本質上探討的是人類大腦如何從環境中提取規則,並形成學習的基礎機制。這種能力不僅是語言學習的關鍵,也是認知心理學中的核心問題之一:人類如何感知、記憶並運用複雜的模式?
因為人類的學習能力並不僅僅依賴知識的輸入,更需要大腦的運算能力。無論是語言學習、視覺識別,還是日常的社會互動,都依賴於各深植於大腦的規律機制,它們支撐了我們對世界的理解與適應。至於如何一一揭開這些神秘機制的運作模式,是認知心理學的研究目標之一。
正如吳嫻所言,「語言」只是探索這些機制的一個切入點。她與研究團隊也進一步將研究延伸至人類「視覺美感」的建構,試圖找出規律感又是如何塑造我們的審美與認知世界。
採訪撰稿/徐瑜棉
攝影/馬藤萍
編輯/馬藤萍
研究來源
吳嫻(2018)。視覺統計學習能力和閱讀能力間的交互影響研究。國科會專題研究計畫(一般研究計畫)。
吳嫻(2020)。以行為和神經造影證據檢驗視覺統計學習能力和閱讀能力間的交互影響。國科會專題研究計畫(一般研究計畫)。
 本著作由人文·島嶼著作,以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本著作由人文·島嶼著作,以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。